DBA自制工具:水平分表时批量生成DDL语句
DBA自制工具这个事情,这么多年下来实践了不少,在职业生涯中踩坑无数的同时靠自制工具也避坑无数。
比如今天要介绍的,就是我在MySQL/MariaDB环境下实施水平分表后,自制了对大量的水平表批量生成DDL语句的运维工具。
实现了这个运维工具的直接好处就是极大地提高了数据库运维的效率和可靠性。

笔者:国际认证信息系统审计师、软考系统分析师
本文需要对水平分表的实践有所了解,以及熟悉MySQL/MariaDB的DDL SQL语法及实际操作。
水平分表
制作这个简单工具的前因是水平分表。水平分表属于另一个话题,所以放在下一篇文章介绍我自己的实践。这里只简要概括一下关键点,在于MySQL/MariaDB的数据分区功能并不能完全符合业务逻辑,以及该功能本身也有一些限制因素,所以采取了在应用程序中按业务逻辑实现动态地把数据分表和操作的机制。
表结构调整
在完成了水平分表机制在应用程序中的相关实现后,一个问题就浮出水面:修改表结构过程的繁琐和易错。
在不依赖数据库自身功能,完全是开发者自主控制的水平分表方式下,如果要修改表结构,就要同时修改所有的水平拆分后所有的平行表的表结构。这意味着修改表结构时写一条ALTER TABLE是不够的,有多少个表就要写多少条,每条命令除了要操作的表名不同之外,其他都是一样的。
当系统运行了两三年后,数据库内就会有几十套平行表,每套平行表调整表结构就要产生几十条ALTER TABLE命令。很显然,任何不想重复劳动的DBA都会想如何批量生成SQL命令。
手工批量产生DDL命令
手工复制粘贴然后手工修改每一条命令的不同处,这一点都不省事。
有点创造力的DBA就会去寻找能批量产生规律性组合内容的工具去产生和填充SQL命令中相互不同的部分。这个工具就是EXCEL(或同类产品)。实际上不仅可以通过EXCEL产生序列,还可以干脆直接地在EXCEL里面产生整条SQL命令。
但这个方法在把SQL命令内容复制出来准备运行之前,必须要做一些处置,比如TAB字符、单引号、双引号、空格和回车字符等等都要先处置,否则执行出错。而且,不同的产品,比如WPS表格或者LibreOffice表格,对这些符号的处理都不尽相同。
程序化自动生成DDL
在反复了好几次利用EXCEL生成SQL的依然繁琐的过程后,开发一个专门产生SQL命令的工具软件的想法就自然产生了。
接下来的剧情就从DBA转入软件开发的分析/设计/开发/测试/实践/调整/回归测试的循环往复了。首先是浓缩为一句话的需求分析:
设计软件工具,由DBA给出模版化的DDL SQL语句,基于该模版DDL SQL语句产生用于生产环境数据库内进行了水平拆分的表的表结构调整的实际DDL SQL语句,语句的执行对象包括作为表结构模版的空表和包含有数据的水平表。
概要设计不需要了,直接开展详细设计。
1)DBA给出用于批量产生的模版化SQL语句
比如:
ALTER TABLE `数据库名`.`表名` ADD COLUMN `新字段名` VARCHAR(10) NULL AFTER `原有的字段名`;
其中,表名是需要变化的,由表名前缀加上时间因素构成,比如tb202011,tb202012这样。时间因素包括“年+月”和仅年份两种。
需要注意的是不要图省事地不写AFTER或者BEFORE这个字段定位说明,即使新增的字段就定位在表的最后。原因是如果表被意外地调整了结构,字段定位说明就有机会引出冲突从而发现意外。虽然在严格的职责分离管理之下这种情况的可能性很小,但作为DBA,必须严谨。
2)按设定的逻辑从模版SQL语句产生需要实际执行的命令
这个“设定的逻辑”再进一步分解如下:
a.从模版命令中获得表名前缀;
b.按表名前缀枚举数据库内已有的平行表;
c.对每一项平行表名,产生替换模版命令中的表名部分后的DDL命令。
上面这个逻辑基本是通的,但细细推敲认为严谨性还是不足。比如表名前缀,如果直接从模版命令中获得,这就存在写错的可能性。
3)既然是DBA,必须考虑操作的可管理性
鉴于数据库内并不止一套被水平拆分的表(基本上每一套可预见数据膨胀的业务流程或功能都已经基于之前的良好实践实现了水平拆分),需要对该水平拆分施加一定的记录管理措施,并通过管理避免发生低级错误,比如前面说的表名前缀人为写错的情况。
在具体设计上,需要实现对应关系定义表,把模版表和经过水平拆分数据的平行表的关系在定义表中明确记录。那么在工具中就可以限制操作人只能从设定的选单中选择需要进行调整的表,各种名字都可以从关系定义表中提取,避免疏忽写错名字。
CREATE TABLE `dt` (
`DT_AutoIndex` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '索引',
`DT_DatabaseName` varchar(20) DEFAULT NULL COMMENT '数据库名',
`DT_TemplateTableName` varchar(30) DEFAULT NULL COMMENT '模版表名',
`DT_HorizontalTableName` varchar(30) DEFAULT NULL COMMENT '水平表名(前缀)',
`DT_MasterTableDatabaseName` varchar(20) DEFAULT NULL COMMENT '主表数据库名',
`DT_MasterTableName` varchar(30) DEFAULT NULL COMMENT '主表名',
`DT_MasterTableNamingFieldName` varchar(50) DEFAULT NULL COMMENT '主表命名字段(不一定是主键)',
PRIMARY KEY (`DT_AutoIndex`),
KEY `DT_DatabaseName` (`DT_DatabaseName`),
KEY `DT_ClassTableName` (`DT_TemplateTableName`)
) ENGINE=InnoDB AUTO_INCREMENT=1 COMMENT='水平拆分关系定义表';
本文只是简化了的说明。在我的实际工作中还进一步地考虑了被水平拆分的表都是子表,因此有必要在这个关系定义表中加入主子表关系说明以及与数据字典表的关联,从而实现更多的限制检查和自动化关联调整,因此上表中有主表信息的字段。
4)最终执行流程的需求确认
基于上述设计,DBA执行调整过程的实际流程大致如下:
a.在测试环境完成变更相关的所有前置工作,比如测试;
b.重组需要执行的DDL SQL语句,形成可以对模版表(前面有提及)的1条结构调整ALTER TABLE命令,作为提供给工具的模版命令。命令中的变化部分,用预定的宏代码替代。
c.使用工具,从工具给出的模版表清单中选择需要操作的表,然后填入模版命令;
d.工具检查并生成需要执行的全部命令。
e.在DBA工具中运行这些命令。
这个过程就不详细说了,简单给个界面设计图说明一下:
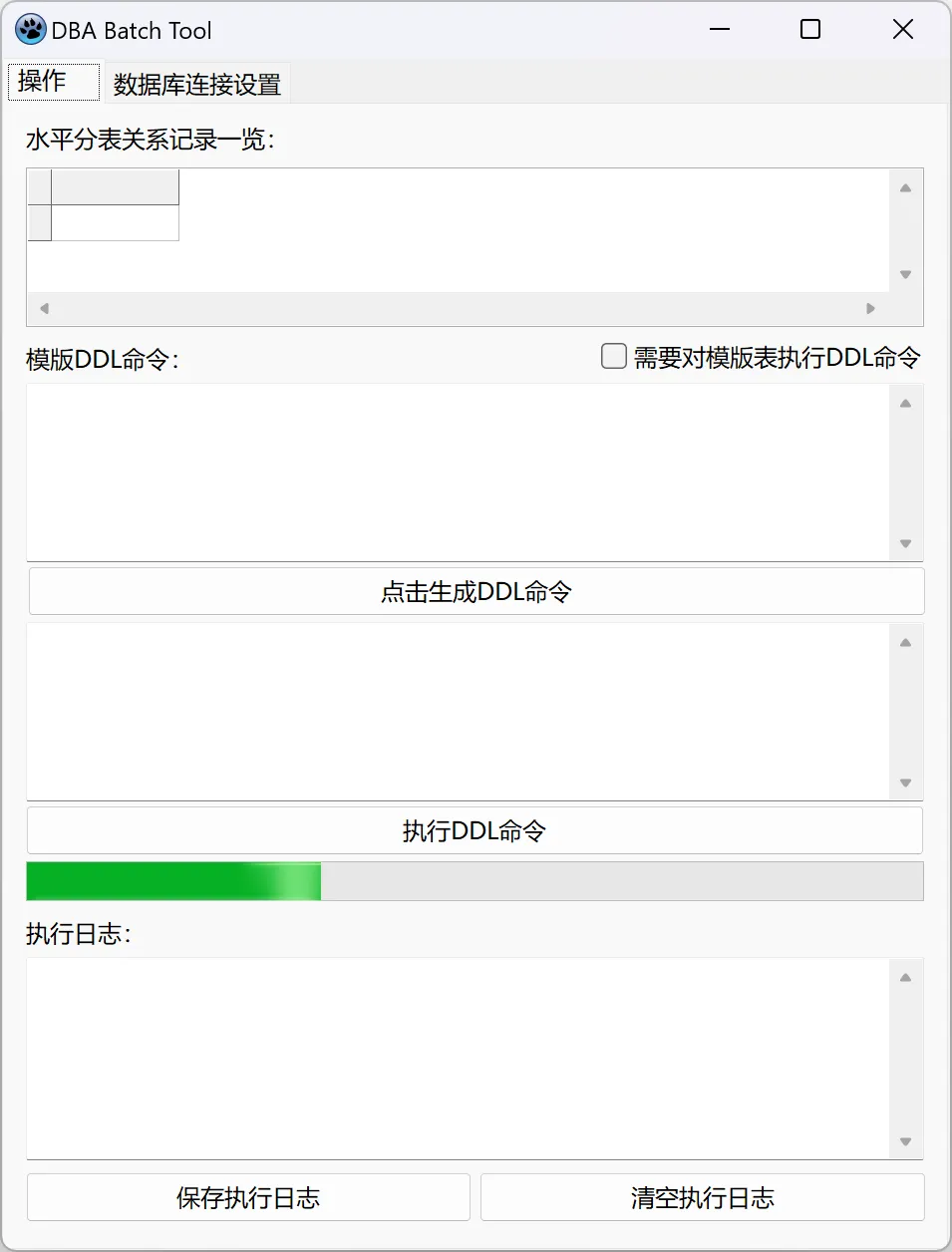
由于各种原因,这个界面图不完全是现在在用的成品,只是充当一个说明。
自己写的这个小工具,实现的功能实际还不止本文介绍的内容。围绕着数据库运维工作的效率和可靠性,还可以进一步地实现以下功能:
对模版DDL语句进行语法检查;
纳入DDL语句执行过程和控制;
DDL执行过程原子化,可回滚;
DDL模拟执行;
DDL执行前触发数据备份;
定时无人值守执行;
分布式高可用性数据库环境的适应性;
等等。
以上功能扩充,实际已经在自己的工具中实现了一部分。如果这个工具还是自用为主,就要避免过度设计,浪费时间;但如果要将其产品化为工具软件,这些扩充就有必要实现。在之前的文章:
一文中描述的自制运维工具发展过程,就是这个思路。
本站微信订阅号:

本页网址二维码: