PHP应对WEB输入攻击,必须应用HTMLPurifier
之所以推荐使用HTMLPurifier,是因为在刚刚过去的年度地区性网络安全攻防演练中,我这边的两套PHP开发的系统面对WEB输入攻击,使用HTMLPurifier与否的遭遇是冰火两重天。
笔者:国际认证信息系统审计师、软考系统分析师
这两套系统都有用WAF设备作为第一重屏障,其中在开发中使用了HTMLPurifier的系统,经受了大量的各种WEB输入攻击尝试依然不倒;而另外一套没有用HTMLPurifier的系统则被各种注入,开发商方面只能疲于奔命地救火。
很显然这和该开发商本身的安全能力存在不足是直接关系,甚至连WEB输入需要集中过滤都没有严格做好。不过这不在本次的讨论内。我们要关注的是在实现了集中的GET/POST输入过滤的前提下,HTMLPurifier所能实现的关键作用。
HTMLPurifier,简单称之为“HTML提纯器”吧,是用PHP开发、对标兼容HTML标准的过滤功能函数库,通过LGPL v2.1+授权许可模式开源。

HTML提纯器基于经过仔细审计、被动式但确保安全的白名单,过滤删除WEB输入中夹杂的恶意代码(XSS攻击,SQL注入攻击等等),并对WEB输入内容与HTML标准的符合性进行修正。所以项目开发者把它不叫过滤器,而是叫提纯器。
与HTML提纯器类似的而且是开源的WEB输入过滤解决方法(函数库)也有不少,但这些解决办法很多没有持续更新,对新的HTML/CSS标准的兼容性有缺陷,也对防御新的攻击手段存在欠缺。
关键在于如何实现过滤的细节上。HTML提纯器的安全性和可靠性在于它是基于白名单放行而不是基于黑名单拦截。网络安全从业人员都知道,黑名单必然会过时,而白名单基于良好审计的前提是完全可靠的。
XSS攻击也好,SQL注入也好,这些攻击手段的成功因素在于恶意利用了HTML规范中一些深层次的规范定义和浏览器实现的误差。这些误差导致恶意代码非常容易变化,从而逃脱基于黑名单的过滤检查。
而HTML提纯器基于白名单过滤机制,对整个WEB输入内容按HTML规范进行分解,检查输入内容中的任何一项HTML/CSS属性,删除任何白名单之外的元素和属性,最后按标准规范校验整理和重新格式化输入内容。
基于以上实现逻辑,HTML提纯器的安全性和可靠性是充足可信的。
HTML提纯器的使用方法很简单,尤其是对于全部环境都是基于UTF-8编码的情况:
require_once './HtmlPurifier/HTMLPurifier.auto.php';
$PurifierConfig = HTMLPurifier_Config::createDefault();
$PurifierConfig->set('Core.Encoding', 'utf-8');
$PurifierObj = new HTMLPurifier($PurifierConfig);
$PurifiedData = $PurifierObj ->purify($MaliciousData);
创建默认配置,设置UTF-8编码,按配置创建对象,调用对象方法执行过滤得到净化后的内容,就这么简单。
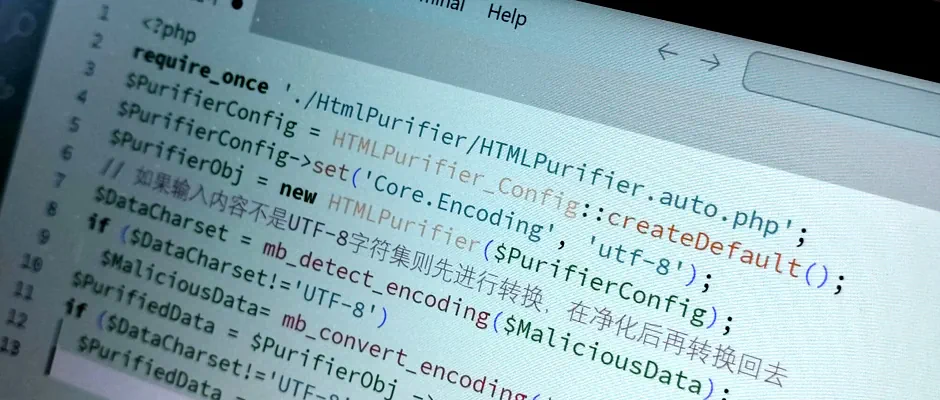
如果WEB环境不是UTF-8而是其他编码,比如使用GB2312或者GBK编码,HTML提纯器需要在调用前先进行转码,然后完成执行过滤纯净化后再转回去原来的编码:
require_once './HtmlPurifier/HTMLPurifier.auto.php';
$PurifierConfig = HTMLPurifier_Config::createDefault();
$PurifierConfig->set('Core.Encoding', 'utf-8');
$PurifierObj = new HTMLPurifier($PurifierConfig);
// 如果输入内容不是UTF-8字符集则先进行转换,在净化后再转换回去
$DataCharset = mb_detect_encoding($MaliciousData);
if ($DataCharset!='UTF-8')
$MaliciousData= mb_convert_encoding($MaliciousData, 'UTF-8', $DataCharset);
$PurifiedData = $PurifierObj ->purify($MaliciousData);
if ($DataCharset!='UTF-8')
$PurifiedData = mb_convert_encoding($PurifiedData , $DataCharset, 'UTF-8');
必须说明的是上面这只是一个很粗略的例子。因为mb_detect_encoding和mb_convert_encoding实际都不能做到100%有效地检测和转换字符集。在应用以上代码时,需要对输入内容的字符集先进行假设,比如假设为GB2312/GBK字符集。
由于mb_detect_encoding在判断中文字符集时还存在一些误判的情况,所以也有人是干脆按中文字符集编码规范自己另外写了一套判断。不过这超越了本文主题,就不展开了,如对此有兴趣可以后台留言。
下面是稍微复杂一些的使用例子:自选过滤保留的HTML标记和CSS属性,并强制所有链接都在新窗口打开:
require_once './HtmlPurifier/HTMLPurifier.auto.php';
$PurifierConfig = HTMLPurifier_Config::createDefault();
$PurifierConfig->set('Core.Encoding', 'UTF-8');
// 可通过参数设置有选择性地过滤XSS,但会大幅度降低性能,除非必要不建议使用。
// 设置保留的HTML标记,格式是:标记名称[属性]
$PurifierConfig->set('HTML.Allowed','div,b,strong,i,em,a[href|title],ul,ol,li,p[style],br,span[style],img[width|height|alt|src]');
// 设置保留的CSS属性
$PurifierConfig->set('CSS.AllowedProperties', 'font,font-size,font-weight,font-style,font-family,text-decoration,padding-left,color,background-color,text-align');
// 设置强制所有的链接在新窗口打开
$PurifierConfig->set('HTML.TargetBlank', TRUE);
// 创建对象并执行过滤
$PurifierObj = new HTMLPurifier($PurifierConfig);
$PurifiedData = $PurifierObj ->purify($MaliciousData);
经过纯净化后的用户输入,就可以放心地用htmlspecialchars函数转义保存到数据库,以及从数据库调取对用户重现了。
如果要说本文的意义,那就是实证了DevSecOps,就是要把安全措施从运维转移到开发环节。WAF设备始终只是一种辅助手段,并不是从根本上解决安全问题的办法。
本站微信订阅号:

本页网址二维码: